
*바쁘신 분들을 위한 3줄 요약
1. List는 데이터가 저장된 주소들의 나열이다. (C언어 Level에서 이중포인터)
2. 데이터 주소만 List에 저장하기 때문에, 데이터 Type이 어떤 것이던지 List로 다룰 수 있음.
3. List는 데이터를 직접 다루는 게 아니기 때문에, Array에 비해 데이터를 다루는데 시간이 오래 걸린다.
List는 어떠한 Data Type도 원소로 다룰 수 있다.
Python에서 List를 다루다 보면, 다양한 Type에 대해서도 잘 동작하는 것을 경험합니다.
>>> import numpy as np
>>> a = [1,2.2,(3,4), "5", np.array([6,7]), {"key8": 9}, 10]
>>> print(a) ## list에 int, float, tuple, string, np.array, dict가 담긴다
[1, 2.2, (3, 4), '5', array([6, 7]), {'key8': 9}, 10]
심지어 function, class도 List의 원소가 될 수 있습니다.
>>> def print_number(num):
... print("function number : ", num)
>>> class Text:
... def __init__(self, num):
... self.num = num
... def print_number_method(self):
... print("method number : ", self.num)
>>> a_list = [1, print_number, Text] ## list안에 function, class도 있다
>>> c = a_list[1](10)
>>> d = a_list[2](20)
>>> d.print_number_method()
function number : 10
method number : 20
List는 어떠한 방식으로 데이터를 저장하길래, 이런 동작이 가능할까요?
List는 데이터들의 주소를 저장합니다.
List를 생성할 때, CPython은 어떻게 동작할까요? 관련 문서를 통해 확인해 봅시다.
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
* list.sort() temporarily sets allocated to -1 to detect mutations.
*
* Items must normally not be NULL, except during construction when
* the list is not yet visible outside the function that builds it.
*/
Py_ssize_t allocated;
} PyListObject;* include/cpython/listobject.h
PyListObject로 된 이 구조체가 바로 Python에서 List 구조를 정의하는 부분입니다. 여기에서 먼저 PyObject_VAR_HEAD부터 알아보겠습니다.
PyObject_VAR_HEAD
인스턴스마다 길이가 다른 객체를 나타내는 새로운 형을 선언할 때 사용되는 매크로입니다. PyObject_VAR_HEAD 매크로는 다음과 같이 확장됩니다:
PyVarObject ob_base;
위의 PyVarObject 설명서를 참조하십시오.
이번에는 PyVarObject를 알아보겠습니다.
type PyVarObject
제한된 API의 일부입니다. (일부 멤버만 안정적인 ABI의 일부입니다.)
이것은 ob_size 필드를 추가하는 PyObject의 확장입니다. 이것은 길이라는 개념을 가진 객체에만 사용됩니다. 이 형은 종종 파이썬/C API에 나타나지 않습니다. Py_REFCNT, Py_TYPE 및 Py_SIZE 매크로를 사용하여 멤버에 액세스해야 합니다.
길이(Length)라는 개념을 가진 자료형은 이 형식을 통해 생성됩니다. 마지막으로 PyObject를 알아보겠습니다.
type PyObject
Part of the Limited API. (Only some members are part of the stable ABI.) All object types are extensions of this type. This is a type which contains the information Python needs to treat a pointer to an object as an object. In a normal “release” build, it contains only the object’s reference count and a pointer to the corresponding type object. Nothing is actually declared to be a PyObject, but every pointer to a Python object can be cast to a PyObject*. Access to the members must be done by using the macros Py_REFCNT and Py_TYPE. (번역 제공 x)
제한된 API의 일부입니다. (일부 멤버만 안정 ABI의 일부입니다.) 모든 객체 형은 이 형의 확장입니다. 파이썬이 객체에 대한 포인터를 객체로 처리하는 데 필요한 정보를 포함하는 형입니다. 일반적인 "릴리스" 빌드에서는 객체의 참조 수와 해당 형 객체에 대한 포인터만 포함됩니다. 실제로 PyObject로 선언된 것은 없지만, PyObject에 대한 모든 포인터는 PyObject* 로 형변환될 수 있습니다. 멤버에 대한 액세스는 매크로 Py_REFCNT 및 Py_TYPE을 사용하여 수행해야 합니다. (*DeepL 번역)
* https://docs.python.org/ko/3/c-api/structures.html
쉽게 설명하자면 모든 Python의 객체는 PyObject에서 시작된다라는 뜻입니다.
정리하자면, PyListObject는 다음과 같습니다.
typedef struct {
PyVarObject ob_base; // PyObject + ob_size : 참조횟수, 타입, 사이즈 엑세스용
PyObject **ob_item; // list 원소 배열의 이중포인터 -> 원소 배열들의 주소 배열
Py_ssize_t allocated; // list에 할당된 메모리 크기
} PyListObject;
**ob_item 덕분에 Python List는 주소값을 저장한 배열이라는 것을 쉽게 알 수 있습니다.
C/C++ Array vs Python list
python list가 실제로 어떤 식으로 데이터를 저장하는지 비교하기 위해 C++경우를 먼저 확인해 보겠습니다.
C/C++ Array의 경우
참고로, C/C++에서 Array는 다음과 같이 선언을 할 수 있습니다.
int arr[5] = {1024, 1025, 1026, 1027, 1028};
그리고 이 값들은 메모리에 그림과 같이 저장됩니다.
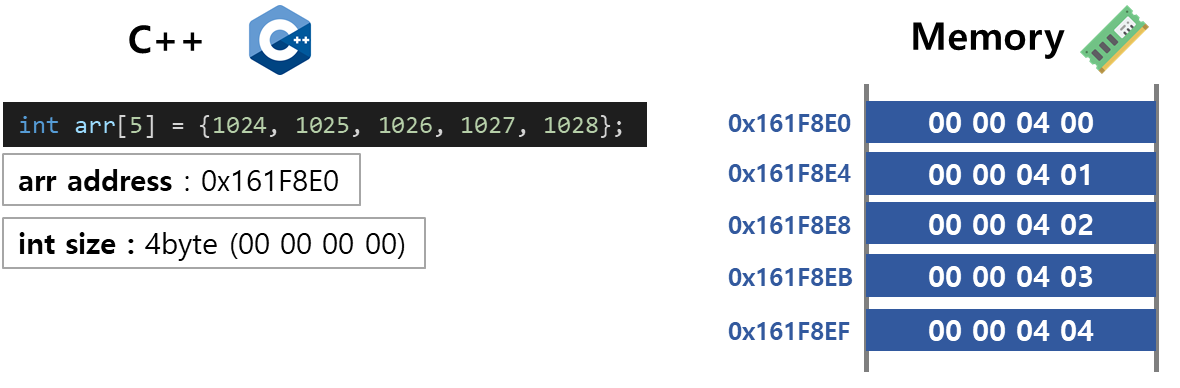
C++에서는 Array 선언은 데이터의 Type을 먼저 정하고(int = 4byte) 그 데이터의 반복횟수(5)를 정합니다. 그러면 정확하게 그 데이터는 총 4byte * 5 = 20 byte 공간이 할당되고, 그 안에서 데이터를 저장할 수 있습니다.
만약에 이런 Array에 갑자기 long long (8byte) 를 저장하려 하면 어렵습니다. 4byte씩 공간이 나눠졌기 때문에 8byte와 같은 크기의 데이터는 들어갈 공간이 없습니다.
Python List의 경우
다음은 Python입니다. Python의 경우 List를 다음과 같이 선언할 수 있습니다.
a_list = [1024, 1025, 1026, 1027, 1028]
그리고 이 값들은 주소의 형태로 저장됩니다.

왜 이 예제는 단순한 숫자 [1, 2, 3, 4, 5]로 진행하지 않았을까요?
이 주소들을 추적하면, 실제 값들을 확인할 수 있습니다.
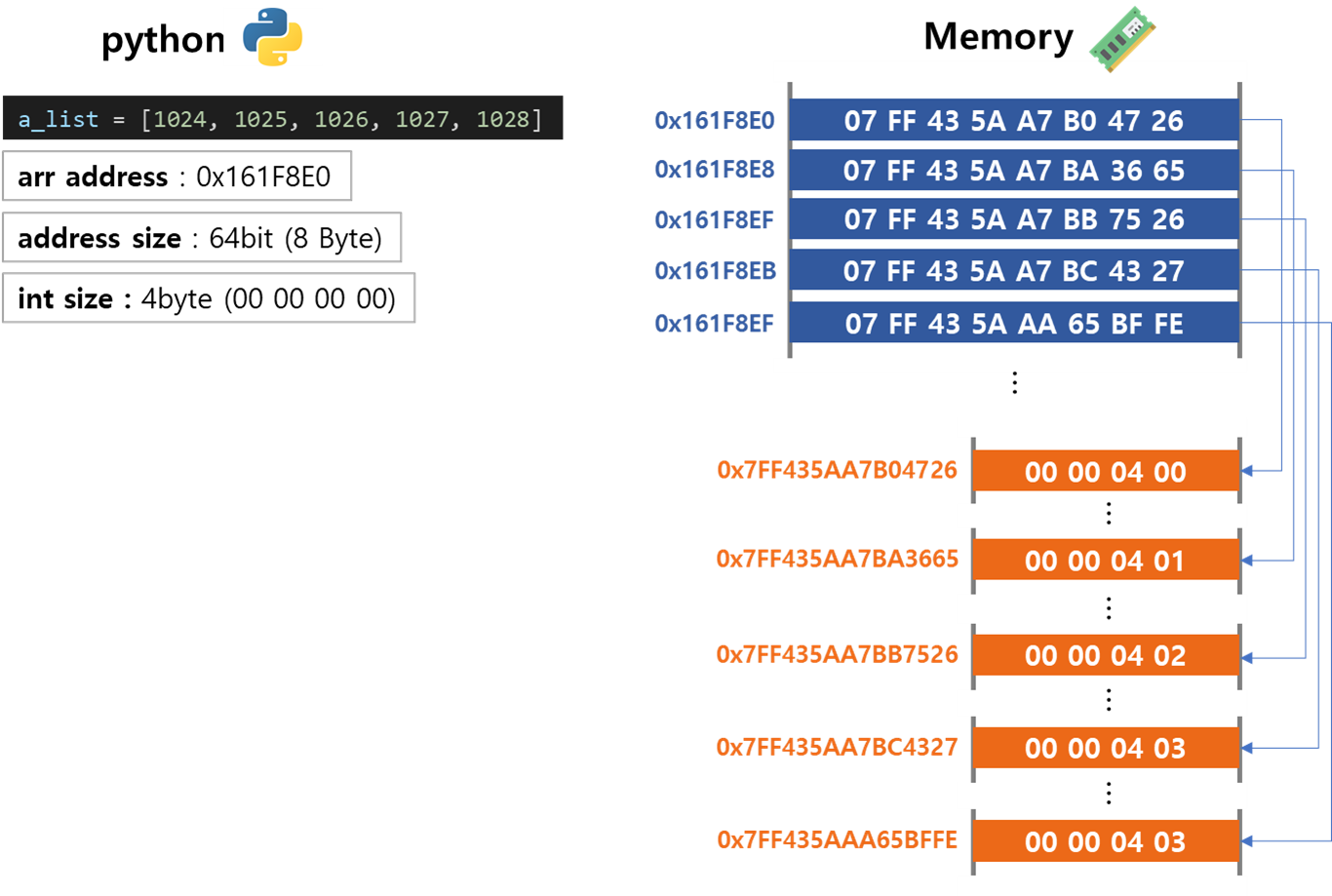
만약에 새로운 형식의 데이터를 list에 저장한다고 해도 list 자체에는 주소만 저장될 뿐, 데이터는 다른 공간에 할당 되기 때문에 C++ Array와 같이 Data size를 신경쓰지 않아도 됩니다.
List는 데이터 자체를 나열해서 저장하는 것이 아닌, 주소만 List에 저장하는 것을 알아보았습니다. 이러한 방식은 List에 어떤 Type이라도 관리 할 수 있는 특징이 있습니다. 장점과 단점을 좀 더 자세히 살펴보면 다음과 같습니다.
장점
1. 데이터의 형식에 구애받지 않는다.
2. 데이터의 append, insert, remove를 쉽게 할 수 있다.
단점
1. 단순 배열에 비해 속도가 느리다.
2. 데이터가 메모리 한 곳에 모여 있지 않아 관련 연산(Vector, broadcasting)이 어렵다.
이러한 단점들을 극복하기 위해 나온 것이 바로 numpy array입니다. numpy array가 궁금하신 분들은 numpy는 어떻게 데이터를 저장하고 관리하는가?를 참고 바랍니다.
* reference
https://docs.python.org/ko/3/c-api/structures.html
'Python > Basic' 카테고리의 다른 글
| Python - List Comprehension (0) | 2023.03.19 |
|---|---|
| Python - Int의 크기가 28bytes인 이유 (6) | 2023.03.01 |
| Python - Mutable vs Immutable (2) | 2023.02.26 |
| Python - 기본 문법정리 (0) | 2023.02.24 |
| Python - is와 ==의 차이 (1) | 2023.02.10 |



